LLM vs Engineering: Why the Model Is the Easy Part
Every LLM can write code and reason. So why do most AI products fail? Because the value isn't the model — it's the agent architecture engineered around it.
What We're Seeing On the Ground
The whole industry is having the wrong argument.
Everyone is fighting about which model is best — this benchmark, that reasoning score, the new release that beat last month's by a few points. Yes, LLMs can write code. Yes, reasoning is improving fast. Yes, every model maker ships a smarter checkpoint every few weeks. All true, and almost completely beside the point for anyone trying to ship a product that works.
Here's the claim, stated plainly enough to argue with: the model is the easy part. Two teams can build on the exact same LLM and ship wildly different products — one reliable and shippable, one that demos beautifully and falls apart in production. The difference isn't the model. It's the engineering wrapped around it: how the agents are architected, how they're orchestrated, how context flows between them, how the system verifies its own work and recovers when it's wrong.
This isn't a Claude story, or a GPT story, or a Gemini story. It's true across all of them. The model is a commodity input you can swap. The architecture is what you actually build — and it's where every real AI product is won or lost. This post is about that architecture.
1. The Number That Ends the "Which LLM" Debate
Let's start with a hard figure, because there's finally a good one.
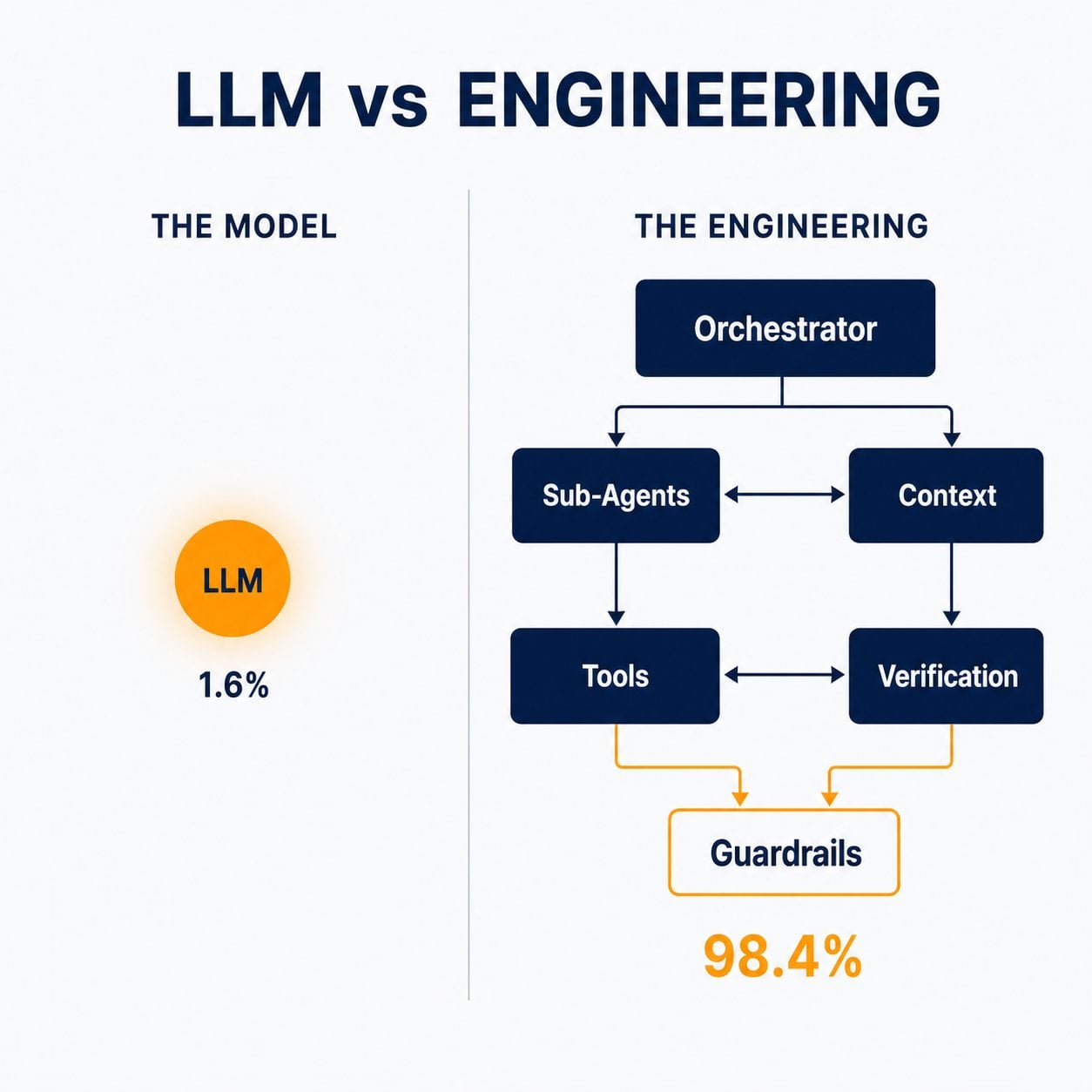
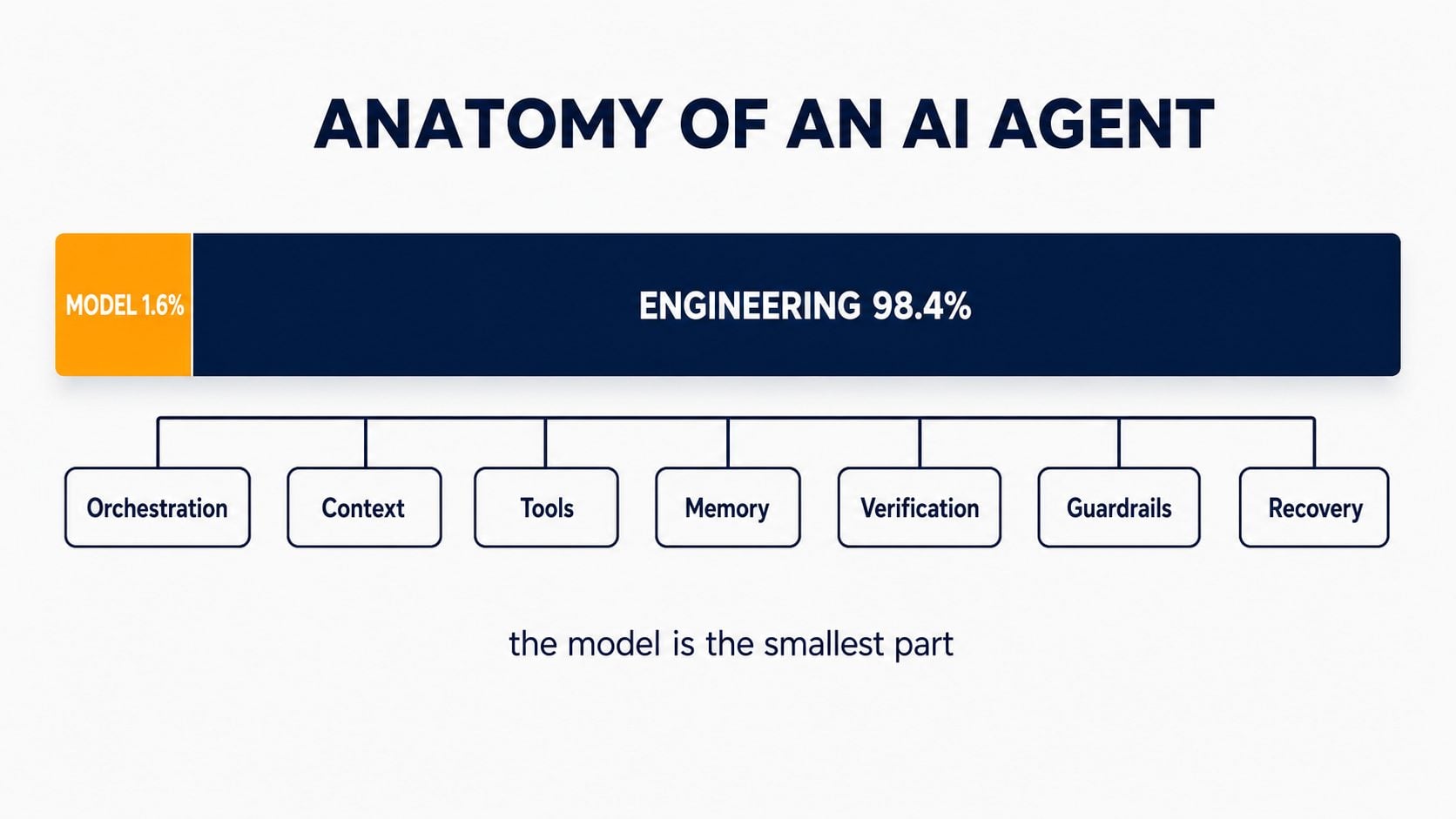
A research team published a source-level architectural breakdown of a leading agentic coding tool — dissecting what the system is actually made of, line by line. Their headline finding: the system is roughly 98.4% infrastructure and 1.6% model. The core agent loop is a simple while-loop. All the real complexity lives in the engineering around it — the orchestration, the context management, the permission gates, the recovery logic.
Read that ratio again. The model call — the thing the entire market obsesses over — is 1.6% of the system. The other 98.4% is engineering.
The same analysis is blunt about why this matters competitively: the loop is trivial to copy; the orchestration, the context handling, and the isolation are not. The architecture resists reimplementation. Anyone can clone a prompt-and-loop in an afternoon. Reproducing the system that makes it reliable across thousands of real tasks is a serious engineering programme.
(Source: VILA-Lab, Dive into Claude Code architectural analysis)
Translation for the boardroom: when a vendor sells you their product "because it uses the latest, smartest model," they've just told you they don't understand their own product. The model is a component everyone can buy. The architecture is the moat.
2. The Model Is the Brain. The Architecture Is Everything Else.
So if the engineering is the product, let's be precise about what that engineering is.
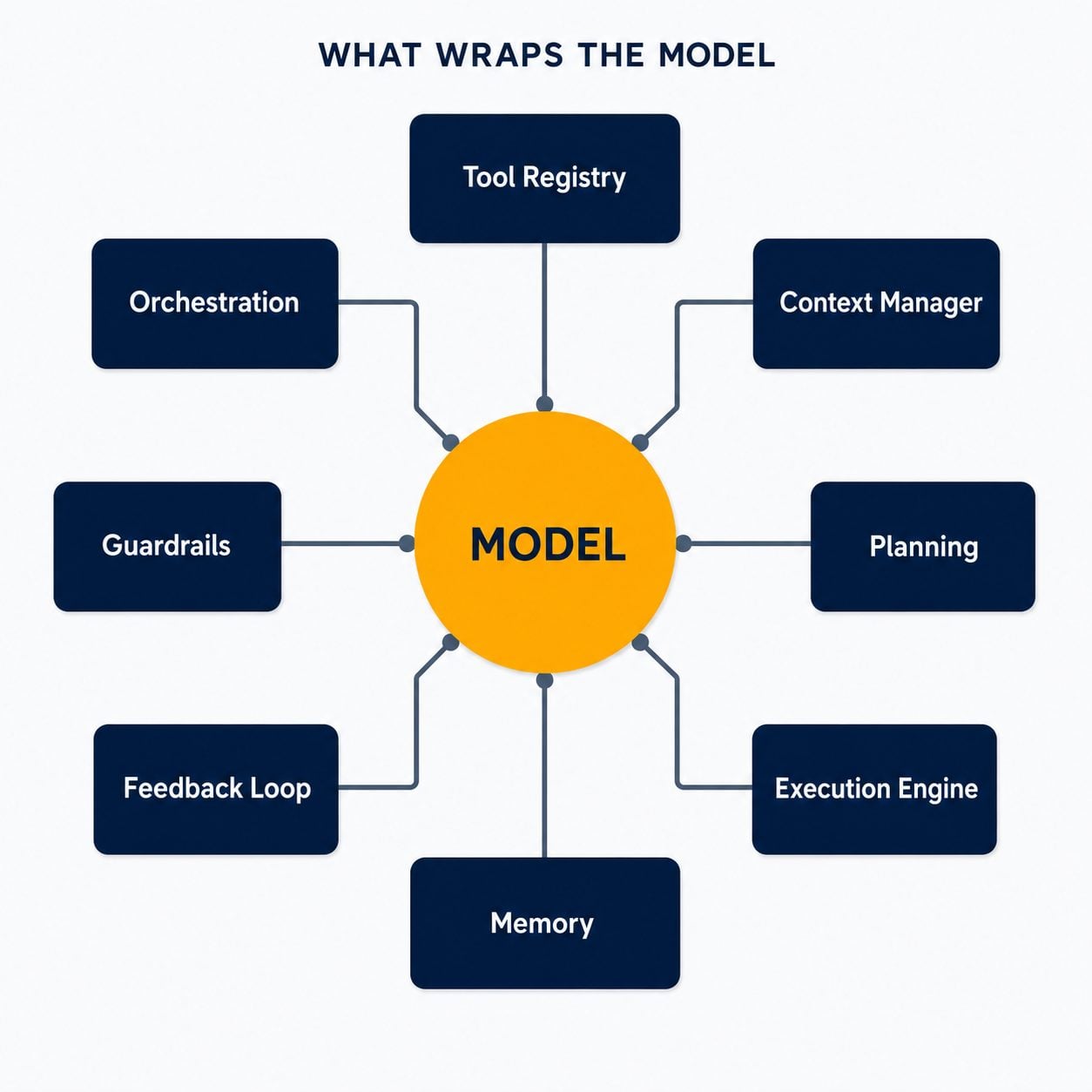
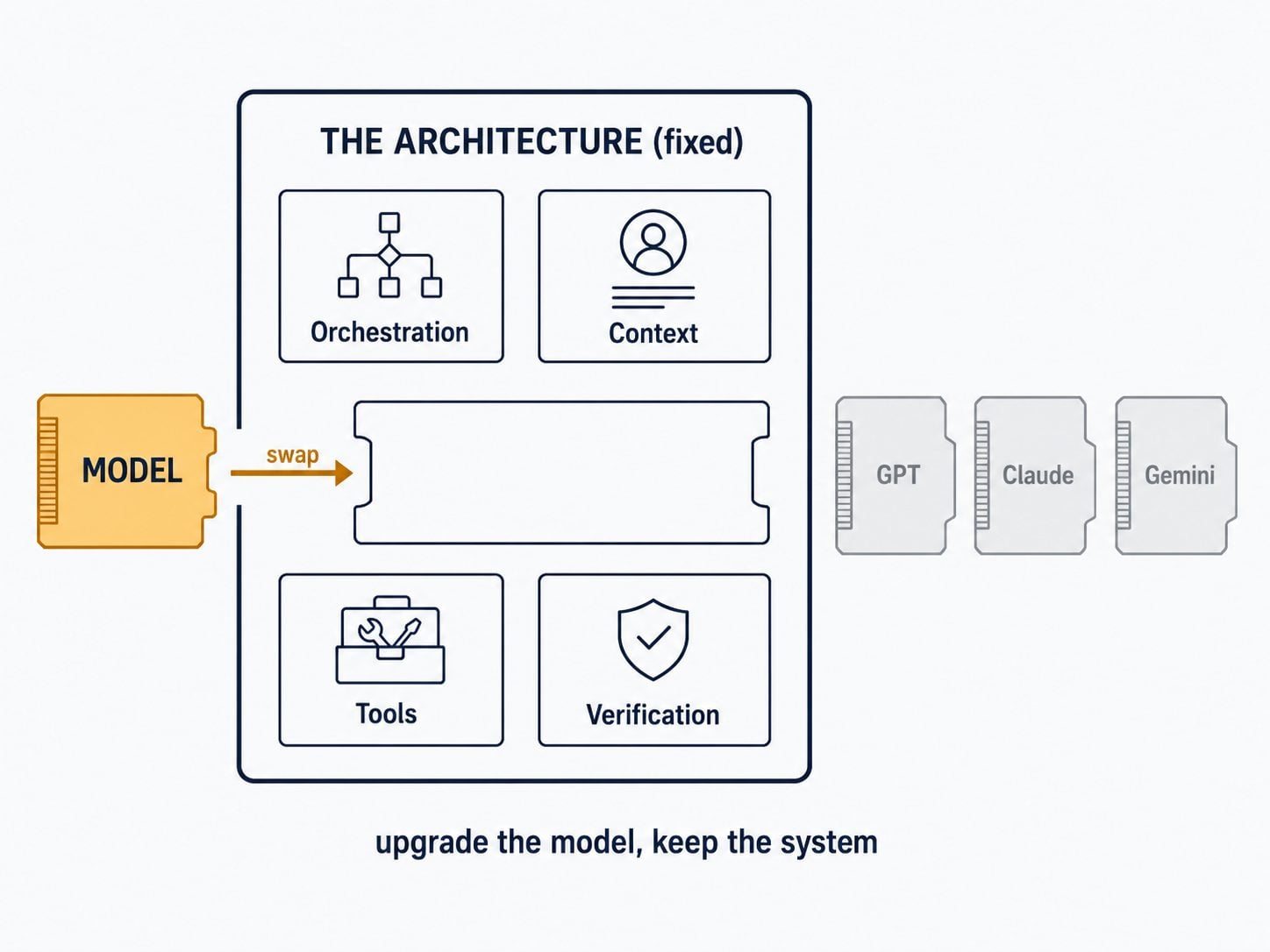
A modern AI agent is a language model wrapped in an infrastructure layer that turns it from something that can say things into something that can do things. That layer typically includes a tool registry, a context manager, a planning module, an execution engine, a memory system, a feedback loop, safety guardrails, and — the focus of this post — an orchestration layer that coordinates multiple agents.
In plain English: the model is the brain. The architecture is the nervous system, the hands, the memory, the reflexes, and the impulse control. A brilliant brain with no hands and no coordination ships nothing.
And here's the part most "LLM vs engineering" takes miss entirely. As soon as you move past a single agent answering a single prompt, the first engineering question isn't "which model?" — it's "how do these agents coordinate?" That coordination model determines your system's latency, fault tolerance, scalability ceiling, and debugging difficulty. Pick the wrong one and you spend months fighting coordination overhead instead of shipping. Let's go through the patterns that actually matter.
3. Agent Architecture Patterns: The Real Engineering
These are the building blocks of every serious agentic system in 2026. They're composable — real products combine several — and choosing between them is the single highest-impact architectural decision you'll make.
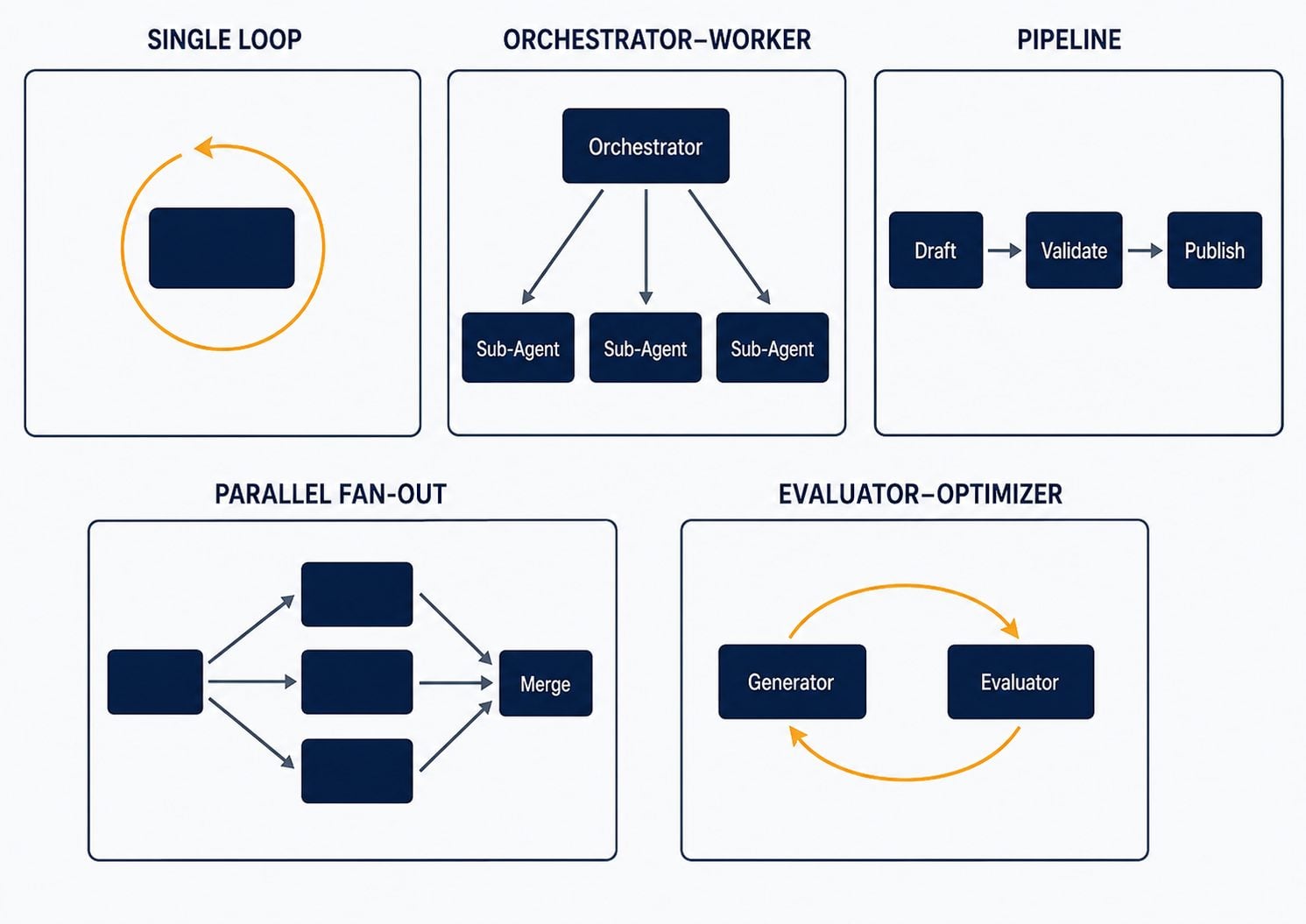
1. The single-agent loop (ReAct). One agent, one context, running the basic loop: think → call a tool → read the result → repeat until done. This is the atom everything else is built from. The "agentic" behaviour isn't magic — it emerges from running this loop until the model decides it's finished. Simple to write. Brutal to make reliable, which is the whole point of this article.
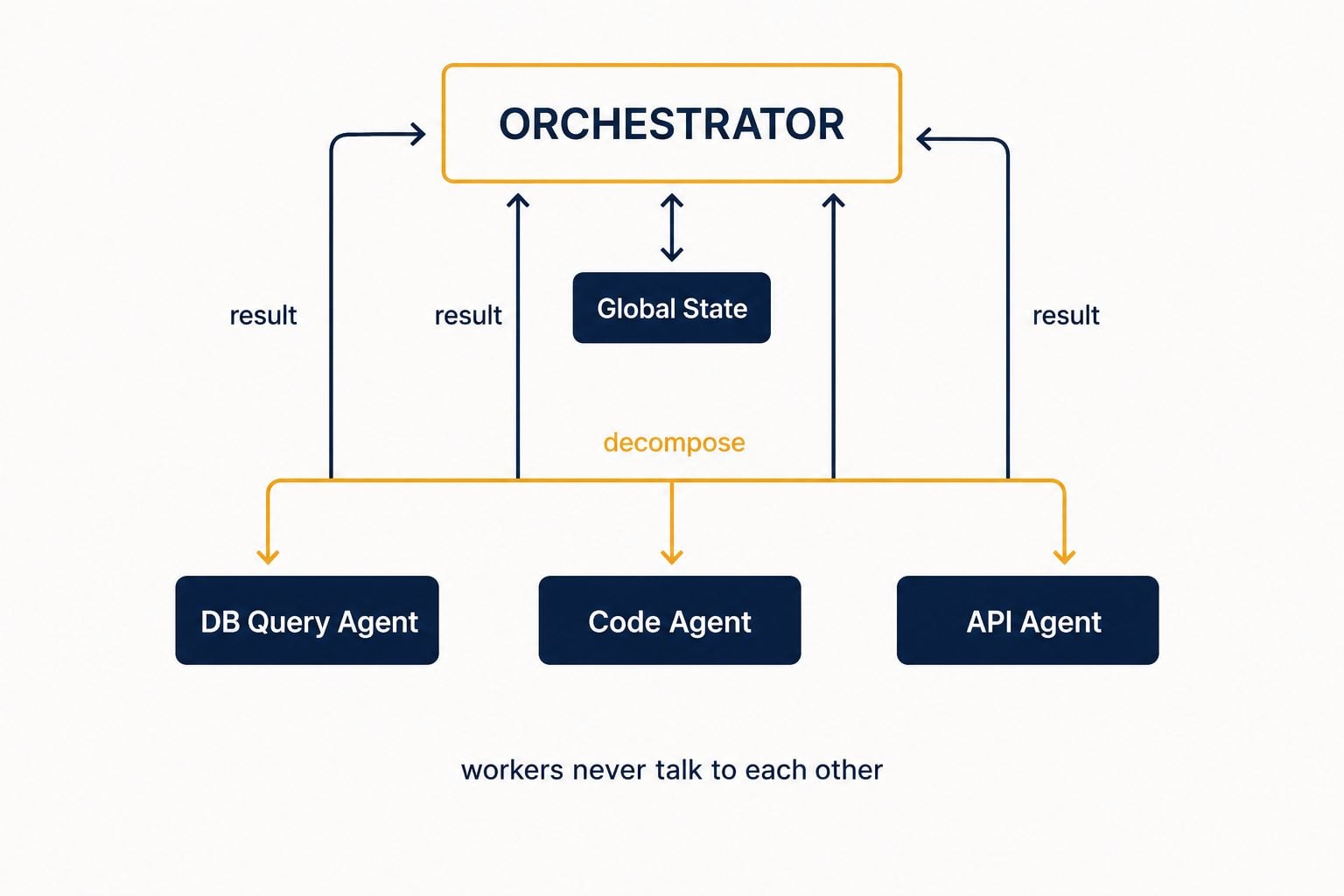
2. Orchestrator–worker (the coordinator pattern). The most widely deployed pattern in production. A single orchestrator agent receives a goal, decomposes it into sub-tasks, and delegates each to a specialised sub-agent — one for database queries, one for code, one for external API calls. Workers don't talk to each other; all coordination flows through the orchestrator, which holds global state, handles error recovery, and decides when the whole task is complete. Hub-and-spoke, applied to AI.
3. Sequential pipeline. Agents arranged in a line, each one's output feeding the next: draft → validate → publish. Simple and effective for well-structured workflows. Drop a validation agent between stages and it can reject weak output and loop it back — a self-correcting pipeline without full orchestration complexity.
4. Parallel fan-out / fan-in. Multiple agents run concurrently on independent sub-tasks, then a reducer merges their results. Dramatically cuts latency when work is parallelisable — but now you're engineering a merge function and graceful partial-failure handling. This is exactly how a bank-to-bank KYC process with 30–40 components runs across parallel branches simultaneously.
5. Evaluator–optimizer (the loop agent). One agent generates; a separate evaluator agent scores the output against explicit criteria and sends feedback for another attempt. The loop repeats until the output clears the bar or hits a cap. Generator and critic as distinct engineered roles — this is how quality stops being luck.
(Sources: Agent Orchestration Patterns — Gurusup; 5 Agentic Design Patterns — Medium; Agentic Design Patterns 2026 — Heym)
4. Hierarchy and Swarms: When You Scale to Many Agents
Two more patterns matter once you push past a handful of agents — and they show why architecture, not model choice, becomes the dominant variable.
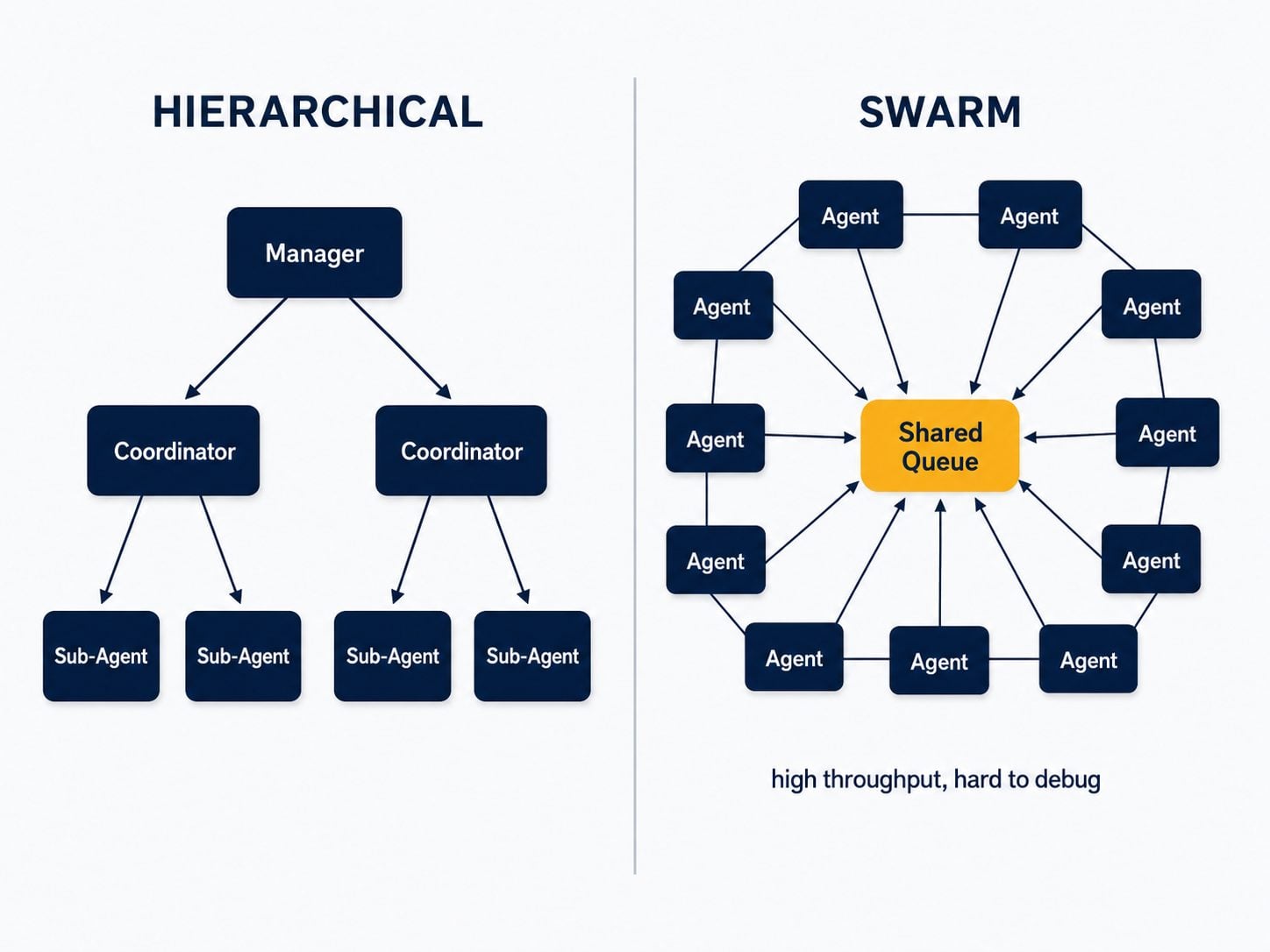
Hierarchical delegation. Orchestrators of orchestrators. A top-level manager decomposes a goal and delegates to mid-level coordinators, each running their own sub-agents — and any of those sub-agents can themselves be orchestrating in parallel, in sequence, or in a loop. This is how genuinely complex enterprise processes get modelled without one agent drowning in scope.
Swarm (decentralised). No single controller. Many agents run in parallel, claim tasks from a shared queue, and coordinate peer-to-peer, with useful behaviour emerging from local interactions. It's the highest-throughput pattern and the hardest to debug. Recent systems have pushed this to extremes — one demonstrated 300 sub-agents executing 4,000 coordinated steps on a single benchmark. Enormous power; enormous coordination risk.
And here's where the engineering gets real. The headline failure mode of every multi-agent system is the runaway loop — agents spawning sub-agents, retrying forever, burning tokens, never terminating. You don't fix that with a smarter model. You fix it with engineering: a hard step budget enforced by the orchestrator (never agent self-reporting), state hashing to detect repeated states and break the cycle, explicit termination conditions defined before the workflow starts, and monotonic-progress checks where each iteration must measurably advance.
(Sources: Swarm vs Mesh vs Hierarchical — Gurusup; Multi-Agent Orchestration Patterns — Lushbinary; AI Agent Orchestration Patterns 2026)
That list — step budgets, state hashing, termination conditions, progress checks — is the answer to "LLM vs engineering." None of it is on a model benchmark. All of it decides whether your product works.
5. Context Is Engineered, Not Prompted
One more layer, because it's the most underrated skill in applied AI and it's pure engineering.
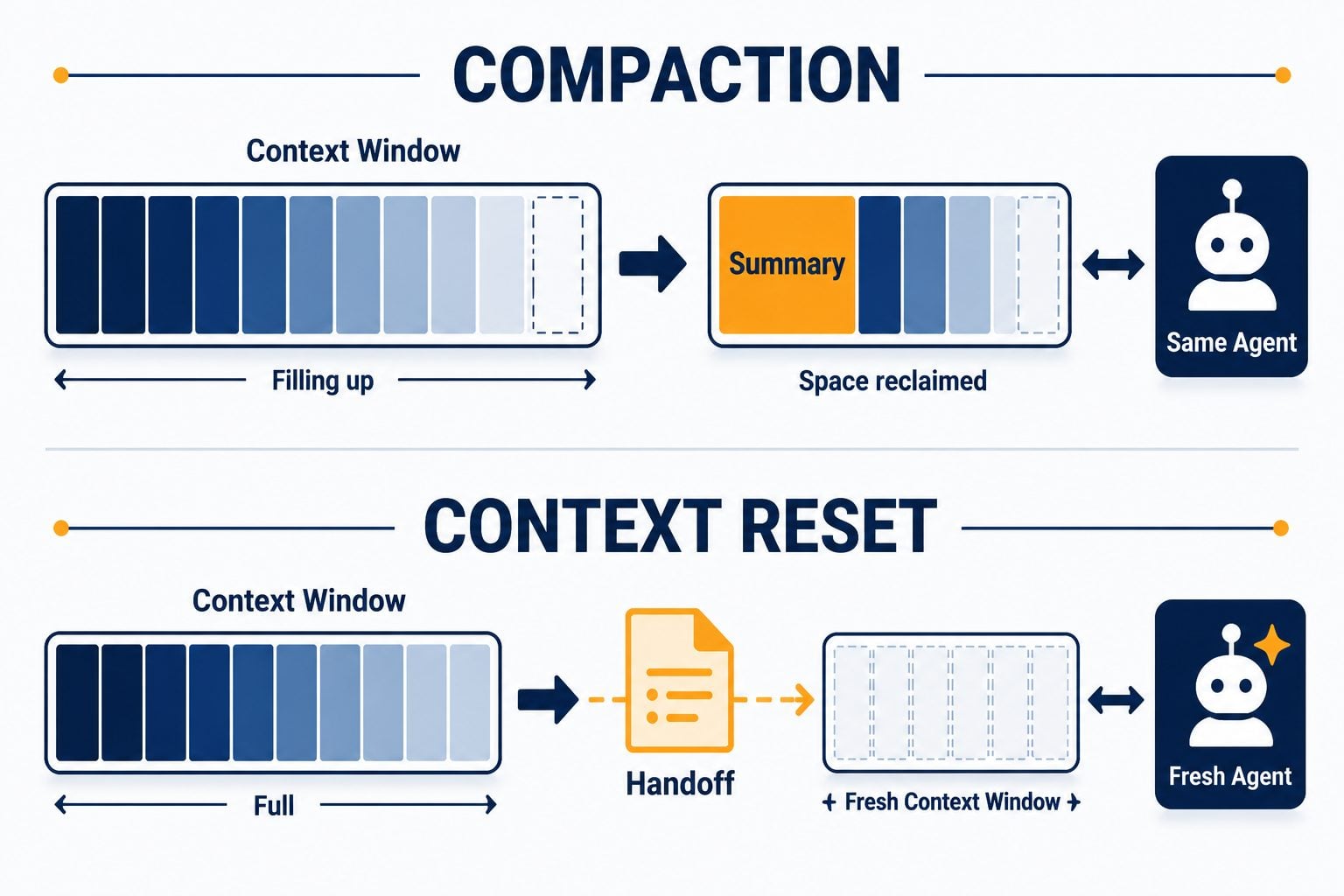
Models lose coherence as their context window fills. Some even wrap up work prematurely as they sense the limit approaching — leaving tasks half-finished. A naive wrapper has no answer. A real architecture has two, and knowing when to use which is the craft:
Compaction summarises earlier conversation in place, so the same agent continues on a shortened history. Preserves continuity.
Context reset clears the window entirely and starts a fresh agent, handed a structured artifact carrying the prior state and next steps. A clean slate — at the cost of engineering a handoff good enough for the next agent to resume cleanly.
For long-horizon work — a multi-document AML investigation, a multi-hour reconciliation — this is the difference between a chatbot that forgets the case halfway and a system that finishes the job. It's also model-specific: the same architecture can behave differently on two different models, so the context strategy has to be engineered around each model's failure modes. That's not prompting. That's systems design.
6. The Symprio Approach: We Architect Systems, Not Prompts
This is exactly the work Symprio does — and exactly why "which LLM should we use?" is the least interesting question a client brings us. Four principles guide how we build.
The model is a swappable input; the architecture is the asset. We design the orchestration, the sub-agent topology, the context strategy, and the verification logic so that when this quarter's best model gives way to next quarter's, you swap the brain without rebuilding the body. Architecture outlives models.
Pattern selection is the highest-leverage decision, so we make it deliberately. Orchestrator–worker for modular enterprise processes, pipelines for structured flows, parallel fan-out for independent sub-tasks, evaluator–optimizer wherever quality must be guaranteed. We match the pattern to the problem instead of forcing everything through one trendy framework.
Loops are governed at design time. Step budgets, termination conditions, state-hash cycle detection, human-in-the-loop checkpoints — engineered in from day one, aligned to BNM, PDPA, AIGE, and the AICB AI Governance Framework. In a regulated environment, a runaway agent isn't a bug ticket; it's an incident.
Adopt-and-build, so your team owns the architecture. We co-build the first multi-agent system with your engineers and transfer the design — so the 98.4% that actually matters lives with your team, not locked in a vendor's black box.
7. What This Looks Like in Practice
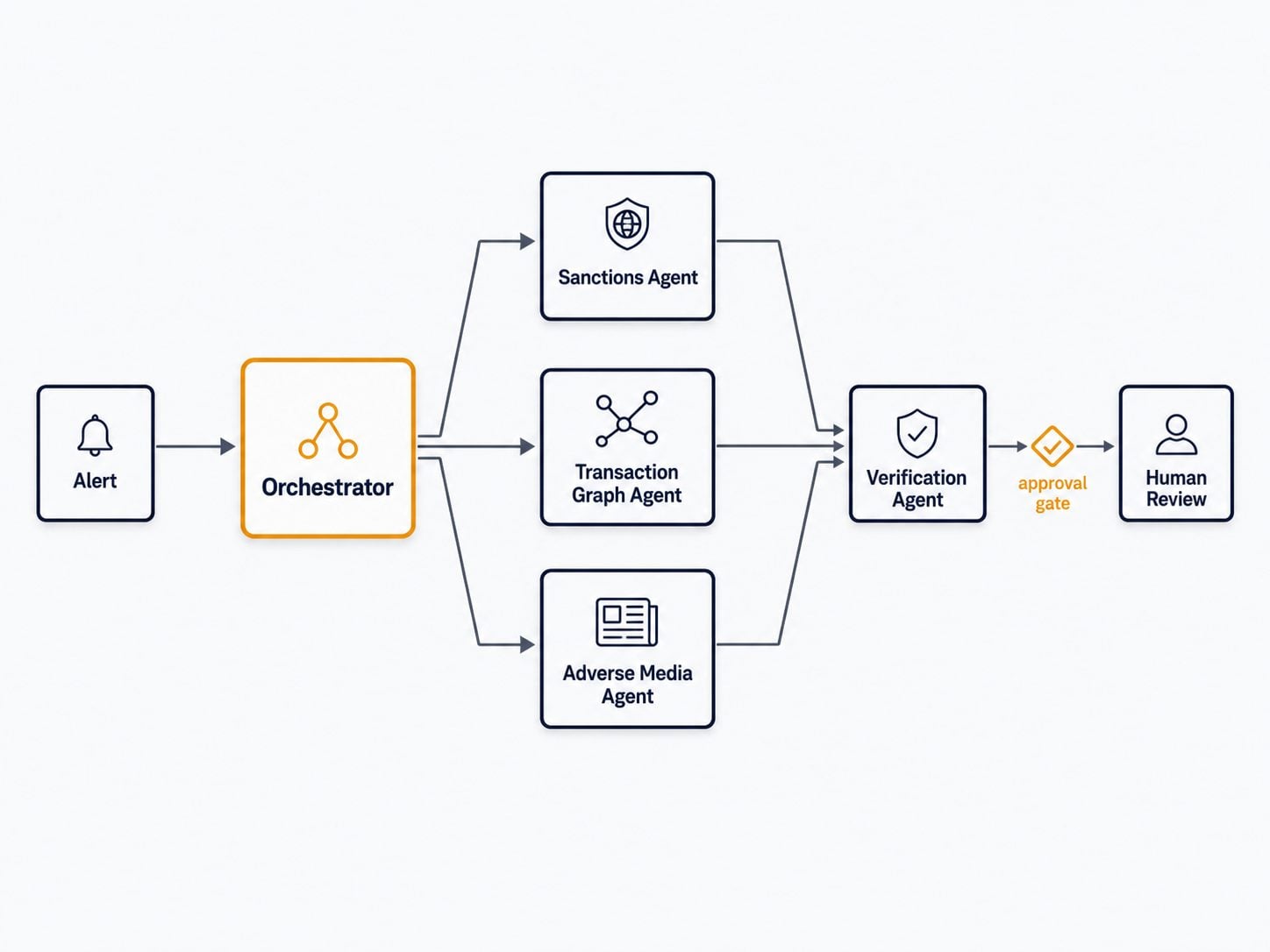
Within 90 days, engineering and product teams typically see architecture-first deployments such as:
An AML / fraud investigation system using an orchestrator delegating to specialised sub-agents (sanctions, transaction graph, adverse-media), with an engineered context-reset strategy for long cases.
A KYC onboarding pipeline running 30–40 verification components across parallel branches, merged by a reducer with graceful partial-failure handling.
A claims intake co-pilot built as an evaluator–optimizer loop, so a separate verification agent checks every output before it reaches a human.
A finance reconciliation system on a swappable-model architecture, so model upgrades are a config change, not a rebuild.
These aren't moonshots. They're what you ship when you treat the architecture as the product and the model as a component.
Frequently Asked Questions
What's the real difference between LLM and engineering in AI products?
The LLM provides raw capability — reasoning and generation. The engineering is everything that turns that capability into a reliable product: agent orchestration, context management, tool design, verification loops, and loop governance. A source-level study found a leading agentic tool is roughly 98.4% infrastructure and 1.6% model.
What are the main agent orchestration patterns?
The core patterns are: single-agent loop (ReAct), orchestrator–worker with sub-agents, sequential pipeline, parallel fan-out/fan-in, evaluator–optimizer loop, hierarchical delegation, and decentralised swarm. They're composable, and choosing between them is the highest-impact architectural decision in a multi-agent system.
What is the orchestrator–worker (sub-agent) pattern?
An orchestrator agent decomposes a goal into sub-tasks and delegates each to a specialised sub-agent, then aggregates the results. Workers don't communicate directly — all coordination flows through the orchestrator, which holds global state and handles error recovery. It's the most widely deployed production pattern.
How do you stop multi-agent systems from looping forever?
Not with a better model — with engineering: a hard step budget enforced by the orchestrator, state hashing to detect repeated states, explicit termination conditions set before the workflow starts, and monotonic-progress checks requiring each iteration to advance measurably.
Does the choice of LLM still matter?
Yes — the model sets the ceiling on capability. But the architecture determines how much of that ceiling the product actually reaches. Two teams on the same model ship very different products depending on their orchestration, context engineering, and verification design.
8. Working With Us
We work with engineering and product teams in three modes:
Architecture review — A half-day deep-dive on your current agent stack — orchestration, sub-agent topology, context strategy, loop governance — with a written recommendation within a week.
Embedded build (8–12 weeks) — One or two Symprio engineers join your team to co-build a production multi-agent system around a specific use case, with full architecture transfer.
Platform partnership — Longer-term engagement to ship a governed portfolio of agents on a swappable-model architecture.
If any of that fits where your team is right now, get in touch →. We'll come back with a one-pager and a timeline within 48 hours.
Request a discovery workshop → · Explore our agentic AI engineering services →
Sources & Further Reading
VILA-Lab — Dive into Claude Code: A Systematic Analysis of Agent Harness Architecture — https://github.com/VILA-Lab/Dive-into-Claude-Code
Gurusup — Agent Orchestration Patterns: Swarm vs Mesh vs Hierarchical — https://gurusup.com/blog/agent-orchestration-patterns
Eduardo Alvarez — 5 Agentic Design Patterns Everyone Should Know — https://eduand-alvarez.medium.com/5-agentic-design-patterns-everyone-should-know-6825cd989178
Heym — Agentic Design Patterns: The 2026 Guide — https://heym.run/blog/agentic-design-patterns
Lushbinary — Multi-Agent Orchestration Patterns: Supervisor, Swarm, Pipeline, Router — https://lushbinary.com/blog/multi-agent-orchestration-patterns-supervisor-swarm-pipeline-router-guide/
JobsByCulture — AI Agent Orchestration Patterns 2026 — https://jobsbyculture.com/blog/ai-agent-orchestration-patterns-2026
Jinba — 7 AI Agent Orchestration Patterns Every Enterprise Architect Should Know — https://jinba.io/blog/ai-agent-orchestration-patterns
Addy Osmani — The Code Agent Orchestra — https://addyosmani.com/blog/code-agent-orchestra/
Anthropic Engineering — Effective Harnesses for Long-Running Agents — https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
#Symprio #EnterpriseAI #AgenticAI #AIArchitecture #MultiAgent #BuildNotBuy #BFSI #Malaysia
Symprio builds AI-enabled products for regulated enterprises — platform-loyal to nothing, loyal to the problem. The model is the easy part. The engineering is the point.